KU-AIAC557-DataAcquisitionManagementSystem
Introduction to Data Science, Engineering and Management
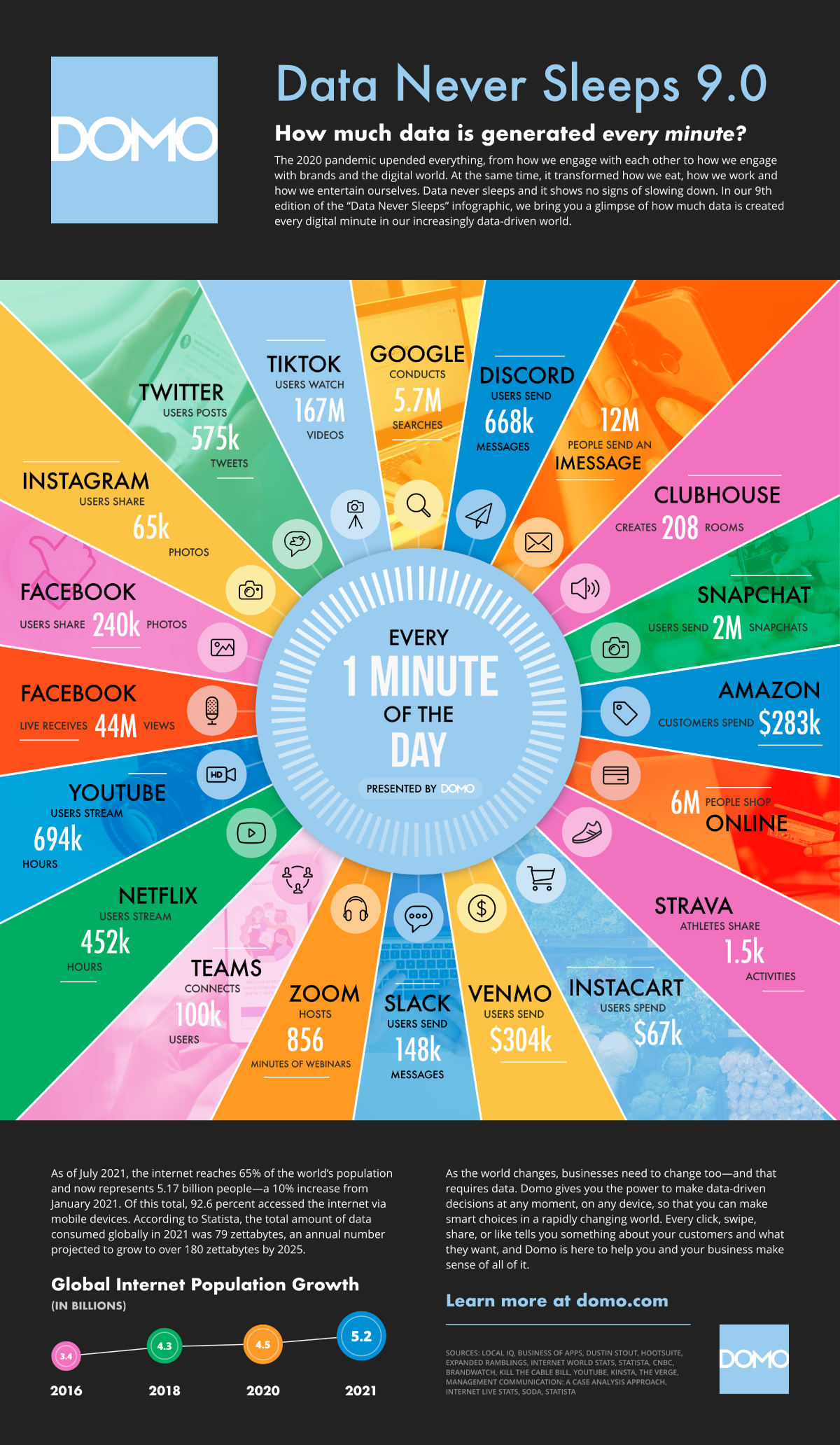
With the growing internet population and growth in technology (IoT, Social Media, Digitialization) the data is growing exponentially everyday.
“As of April 2022, the internet reaches 63% of the world’s population, representing roughly 5 billion. Of this total, 4.65 billion — over 93% — were social media users. According to Statista, the total amount of data predicted to be created, captured, copied and consumed globally in 2022 is 97 zettabytes, a number projected to grow to 181 zettabytes by 2025.” - Data Never Sleeps
We are generating data through events (Internet of Events, Internet of Everything):
- Pre-Internet (Human-to-Human): Data Creation and transfer through devices, Telephony, SMS, Other Communication Means
- Internet of Content (WWW or Web 1.0): Email, Websites, entertainment
- Internet of Services and Processes (Web 2.0): Event Data, E-Productivity, E-Commerce, E-Banking, Digital Finance, Stock Exchange, Event Logs, Software Logs, Ticket Booking, E-Payment,
- Internet of People (Social Media): Connection of People: Facebook, Youtube, Skype, Zoom, Twitter, Reddit, Quora, …
- Internet of Things (Machine-to-Machine): Growth of Smart Devices and data generated through sensors
Data is a unique asset
Data is an asset from which enterprises can derive ongoing value through strategic planning & coordination. Data and information are vital to the day-to-day operations of organizations, hence it has been named the “New Gold”, the “New Currency”, the “Life Blood”, “New Oil”, and so on. Failure to manage data is failure to manage capital. It results in waste and lost of opportunity. Data can give enterprise insights about their existing and potential customers, their products and services, and interal processes which can enable making better decisions that drive future values.
Just like valuation of goodwill, it is important to valuate data and its likely that we’ll see a record of data valuation in P&L chart. But valuation of data is not standardize, it is contextual (data valuable for organisation might not be relevant for other) and temporal (data valuable now, might not be useful tomorrow). Data has unique properties that makes it challenging to manage and valuate.
- Intangible
- Durable: It doesn’t wear out with use
- Temoral: It can get obsolete and devalued over time
- Duplicable: It is easy to copy and even transport but not-reproducible if destroyed
- Since, data doesn’t get consumed when used, it can be stolen without notice
- Can be used by multiple people at the same time for different purpose
- Use of data can generate more data
- It has certain quality and needs a lot of work to maintain high quality
- MetaData (data about the data: source of data, data lineage, ownership, rights on,) is required to manage data as an asset, which itself is a data to be managed.
- Data has a dynamic lifecycle: it gets created/obatined, moved/transformed, Used and Disposed aligining with the product lifecycle.
- Data has unique risks, not just being stolen for value, but also for being stolen for misues. There’s also a risk of being misunderstood because of the information gap of what is known and what is required to know to make effective decision.
- Different tools are required at different phases of its lifecycle
Data Information Knowledge Wisdom (DIKW) Pyramid
The goal of data science and engineering is to convert data into information and information into knowledge or actionable insights, which gradually changes into wisdom.

DIKW pyramid aka DIKW hierarchy shows structural/functional relationship or stages of data as Data, Information, Knowledge, and Wisdom, also explained through other types of diagrams. Data such as facts, signals, symbols that are organized into meaningful and informative structures, through certain integrations, aggregations and other processing, are termed as Information. Knowledge is defined in reference to relevant and contextual information which can be put into actions through certain subjective interpretation or other cognitive processes. Applied knowledge becomes experiences and wisdom for the organization; wisdom is non-material amd more about human judgments and decisions for using the knowledge for greater good. The more we process the raw data volume or size gets compressed giving more value from it, but at the same time it might lose some information.
A lot of work needs to happen to convert data to information and to knowledge. The data are acquired, cleaned, explored, processed/transformed, moved, integrated, validated, stored and visualized through multiple pipelines to get the data to end user for data-driven decision making. The process of extracting knowledge was initially appeared in database mining where the term “knowledge discovery in databases” (KDD) was coined; KDD process is commonly defined with the stages: Selection –> Pre-processing –> Transformation –> Data mining –> Interpretation/evaluation. However, there are many variation of this theme, and many attempts to standardize the processes one such open standard process model is CRoss-Industry Standard Process for Data Mining (CRISP-DM) conceived in 1996 through the effort of a consortium which is currently adopted by IBM and other organizations. Another standard developed by SAS is SEMMA which stands for Sample, Explore, Modify, Model, Assess; however CRISP-DM incorporates all the stages in SEMMA and KDD with addition of business understanding and deployment stages as well.

Various stages and numerous data tasks requires unique skills and hence disparate data-related roles and responsibilities have emerged mostly Data Scientist, Data Engineer, and Data Analyst.

- Data Engineering: building pipeline systems to enable data ingestion and integration from multiple sources, storing and processing them to provide correct data in right form to right people efficiently
- Data Analytics: process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, informing conclusions, and supporting decision-making.
- Data Wrangling (Data Munging): Transforming and mapping data from one “raw” form into another format with intent of making it more appropriate and valuate for a variety of downstream purposes
- Data Aggregation
- Data Visualization
- Data Science: uses scientific methods, processes, algorithms and systems to extract or extrapolate knowledge and insights from noisy, structure and unstructured data and apply knowledge from data across a broad range of application domains. It is an interdisciplinary science which requires programming skills, mathematics as well as substantive domain expertise.
- Data Mining: analysis step of the knowledge discovery in databases (KDD) process where patterns are extracted or discovered from large data sets into a comprehensible structure for further uses.
- Big Data: data sets that are too large or complex to be dealt with by traditional data-processing application software which brings challenges at every stages: capturing data, storing, analyzing them, searching/querying, updating, transferring, visualization and hence require different tools and techniques to deal with them.
Data Scientist was called the sexiest job of 21st century in 2012; however by 2020 the focus shifted more towards Data Engineers. Some companies even expect data scientists to be full-stack with data engineering and data ops knowledge including containerization and infrastructure tools. Furthermore, The expectation from data engineer has grown a lot. Data Engineers are expected to come back with a solution within hours which could take days a decade back. A data engineer, today needs to do a lot less from scratch and spend less time on setting up and managing systems. Data science and engineering is a team sport, no one person is expected to have all the knowledge, skills, and specializations required for the wide-ranging tasks covered within the scope of data engineering.
Data Analytics Value Escalator
Data Management Principles
Data Strategy
Strategic use case areas
- Using data to make better informed, fact-based decisions
- It helps clear about key information needed, Questions descision-makers need to answer through data dashboard and self-service data exploration tool
- Helping you better understand your customers and markets
- Using Data to offer smarter services and more intelligent product
- improving and automating your business process with data
- Data monetisation